Система локализации в Unity с точки зрения разработчика
Про что статья
Мы сделали систему локализации. Рассказываем как работает и в чем смысл делать свою систему, а не брать готовую.
Когда-то мы с Александром Штаченко писали статью на эту тему http://progamedev.net/localization/ (с упором на общие моменты). В этой статье больше про наше решение будет.
Кому статья будет полезна: тем кто собирается разрабатывать свою систему локализации (или писать на неё ТЗ), тем кто выбирает готовую систему локализации для своего проекта и не знает на что смотреть, тем кто хочет починить процессы, связанные с локализацией, но пока не понимает на что обратить внимание и как именно чинить.
С чего всё началось
В 2005 году мы отдали на локализацию локкит игры «Магия Крови». Переводили в сумме на 13 языков четырьмя командами локализации. В процессе конечно же появились правки и пришлось синхронизировать разные версии локкитов от разных команд перевода. То что мы вообще её перевели и выпустили — частично заслуга крутанов от нашего издателя Deep Silver, которые параллельно сами делали LQA, и вообще с ними было очень комфортно работать.
Кратко опишу с какими проблемами мы столкнулись:
- Замена нового текста уже переведенным старым
- Нахождение переводчиком смысловых ошибок в тексте оригинала (что повлекло правки)
- Смещение строк при копировании на 1 строчку (в итоге сломался весь текст, долго искали)
- Не попадание части строк в обновленный локкит, так как их вставили в середину и не заметили (текста было ОЧЕНЬ много).
- Перепутали версию локкита и вставили старый вместо нового
- Excel (в котором мы хранили тогда данные локализации) заглючил из-за какого-то символа и поменял кодировку при экспорте в CSV (который использовал движок)
- В svn несколько человек могли поправить файл, а мерджить xls с раскраской было не очень весело. Приходилось решать конфликты сравнивая оба файла руками (а xlsx и нормального мерджа для экселя тогда ещё не было).
- Ну и ещё куча других проблем
Постановка задачи
В итоге когда в своей студии я решил сделать систему локализации, то постарался учесть все эти проблемы на этапе подготовки ТЗ. Мы выписали что нам нужно уметь делать (“типовые сценарии”) и что нам точно не понадобится (“точно не нужно”). Параллельно мы изучили все существующие на тот момент системы локализации для Unity и частично для веб, чтобы не изобретать велосипед, и только потом начали делать свою.
Для кого эта тулза и какие задачи она решает
Система локализации которую мы делали — прежде всего для разработчиков. Она НЕ для переводчиков. Поэтому в ней нет памяти переводов, подсчета повторов, расчета стоимости и других функций, которыми пользуются переводчики.
Также эта тулза не занимается доставкой контента (загрузка на CDN, версии билдов и т.п.), это задача другой системы.
Что она делает:
- позволяет добавлять и редактировать ключи
- позволяет отдавать тексты на перевод и вставлять перевод в игру
- показывает тексты на выбранном языке (отдаёт в код значения на нужном языке со всеми подстановками)
- проверяет те ошибки, которые можно проверить без участия человека и исправляет их, если это можно сделать автоматически.
Что нам не понадобится
- Несколько базовых языков. Мы планировали что все тексты будут изначально писаться на одном языке, а потом уже переводиться на все остальные. Несколько базовых языков могут понадобиться, например, если вы делаете User Generated Content и авторы аддонов могут писать на любом языке.
- Мы сразу решили что нам не понадобится компонентная система подстановки текстов. Что это такое? Это когда на все текстовые компоненты цепляется скрипт и оно само заменяет текст и обновляет его. Нас такой подход не устраивал, так как не хотелось каждый апдейт менять текст если это не требуется (тормоза и неконтролируемость). Вместо этого все поля в нужный момент обновлялись из кода по событиям. Ссылки на нужные текстовые поля заполнялись в конструкторе.
Пример компонентного подхода:
 |
Пример подхода с добавлением из кода:
| button.text = LL.get_text(“mybutton.text”); // нужные тестовые поля в префабе окна в паблик поле класса окна добавлены и заполняются в конструкторе окна, а обновляются в апдейте окна при изменении или в своём апдейте если нужно |
- Использование формул прямо в тексте локализации. Под формулами подразумевается что я могу взять n переменных, и прям в локали написать формулу формата “{текущее_здоровье}/{макс_здоровье}*100%” — и оно выведет не через слэш, а именно процент. Мы сочли такую идею нездоровым примером programmer way запутывающим переводчиков, а также решили что автоматический поиск ошибок в этом случае будет затруднён. Такие вещи надо делать в коде, а не в локализации.
Типовые задачи
- Все текстовые значения доступны по осмысленному текстовому ключу-техимени (Dictionary <key, value>). На тот момент мы изрядно намучились с числовыми “ничего не говорящими” айдишниками в одном из проектов, который издавали с Диснеем и решили не повторять этой ошибки.
- Мы хранили все данные проекта в git, поэтому нам важно было уметь решать конфликты (когда несколько человек поправили один и тот же файл, иногда в одном и том же месте). Также нам нужно было хранить UTF-8 данные (на разных языках) в одном файле. Поэтому выбор был между двумя форматами которые человек может читать в виде текста: xml и json. Мы выбрали xml так как уже читали из него конфиги. Бинарные форматы неудобно мерджить и мы не стали использовать их для хранения.
- Мы решили, что нам удобнее разбивать файлы не по языкам (как правило обновления всё равно выкатываются с переводом на все языки сразу), а по смысловым группам. Например, поправили ключи раздела “интерфейсы” и поменялся только файл с интерфейсами. По языкам удобнее разбивать, если вы хотите дать возможность пользователям добавить свой язык отдельным файлом, а не править общий локкит. Мы решили что проще добавить возможность override (замены) если это понадобится в дальнейшем (пока не понадобилось).
- Мы сразу решили что в тексте понадобятся параметры для подстановки. Типичный пример: «Игрок {_killer_name_} убил игрока {_target_name_}. {_killer_name_} получил в награду {_reward_} ». Все имена параметров также были осмысленными, а не «%1». Это позволяет переводчику понимать контекст фразы лучше.
- Типичные действия:
- добавить новую строку,
- заменить текст строки,
- найти все строки которые требуют перевода,
- отдать их на перевод,
- получить переведенный текст,
- проверить что там ничего не сломано технически (например, совпадает кол-во параметров).
- если есть ошибки, найти их и отдать на повторный перевод
- сохранить в игру.
- Все эти действия в реальной жизни могут совершаться в ПРОИЗВОЛЬНОМ порядке, что создаёт немало проблем. Как мы эту проблему решили я расскажу дальше.
- автоматические проверки всего что можно проверять автоматически.
- При работе с интерфейсами часто текст перевода не влезал в отведенное поле. Например, на немецком целое предложение может быть записано одним словом, а длина слова в разных языках отличаться в 3-4 раза. Эту проблемы мы решили вводом отдельного языка “самый длинный” (из всего локкита выбирались самые длинные фразы и подставлялись в интерфейс). QA сказали нам спасибо.
- В приложении мы хотели выбирать язык как вручную, так и автоматически (например по GEO пользователя, если оно доступно). В случае если перевода на этот язык нет, мы выбирали “дефолтный” язык (как правило это английский).
- Часть языков мы ещё не до конца перевели, так что мы в редакторе хотели иметь возможность пометить какие языки пойдут в релиз, а какие не финальные и в релиз попасть не должны. Это позволяло, например, держать 15 языков с гуглопереводом для тестирования размеров полей в интерфейсе и 4 основных языка на которые перевод сделан нормально.
- Для автоматической синхронизации разных локкитов мы добавили версионность каждой строке и каждому переводу. Это избавило нас от ручной проверки и части описанных ранее проблем.
- Мы хотели уметь ограничивать размер текста (например, для названия приложения и его описания для стора).
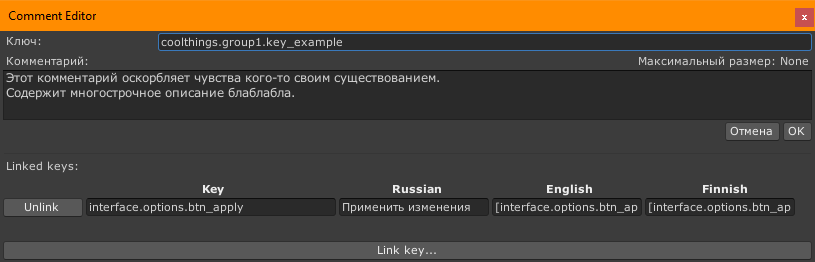
- Мы хотели дать максимум контекста для переводчиков, а также по возможности обеспечить единообразие перевода одинаковых названий, но при этом не использовать подстановки там где это не требуется (потому что это плохо сказывается на качестве перевода). В итоге мы добавили поле комментариев куда помимо размера текста можно было дописать произвольный комментарий и прилинковать связанные ключи-техимена, чтобы переводчик мог найти нужный стат или предмет/персонажа и понять о чем речь в тексте.
- Мы хотели контролировать что попадает в локкит игры и не заливать в репозиторий заведомо неправильные изменения. Для этого нужно было разграничение прав доступа и назначение ответственных за заливку.
- Мы не хотели чтобы переводчики переводили вообще все тексты которые сейчас есть в игре. Часть из них могут быть не финальными и тратить деньги на перевод дебажных текстов не стоит.
- Мы хотели отдавать текст в удобном формате. Большинству переводчиков был удобен формат excel/google sheets, на последнем мы и остановились. Но хранить в нём данные игры и синхронизировать их крайне неудобно.
- Генерация кода. Для некоторых строк довольно удобно сгенерировать методы, чтобы не писать кучу лишнего кода. Мы сделали генерацию класса с такими методами для тех строк где это нужно.
- Фолдинг. Мы хотели однотипные ключи помещать вместе и уметь “сворачивать” их. В итоге мы условились, что точка в названии ключа является разделителем. Пример: «interface.options_window.tab_sound_settings». Так мы можем легко найти все ключи от одного окна. При выгрузке они все будут рядом в таблице.
- проверка на то разрешены ли несколько линий (multiline) в конкретной строке. Мы решили в случае ручного перевода строки проверять совпадение кол-ва переводов строки для всех языков. Также всегда можно добавить тег неразрывной строки <nobr>.
Псевдо-локализация
Псевдо-локализация — это метод тестирования локализации вашего приложения на ранних этапах разработки, до того как вы действительно начнете делать перевод на другие языки. Суть в генерации машинного перевода и подстановке его в качестве текущего. Позволяет обнаружить проблемы, которые могут возникнуть при после вставки реального перевода.
Типичные проблемы, которые так можно решать:
- Ограничение на размер в интерфейсе: Области в интерфейсе, в которые может не поместиться переведенный текст, из-за чего он некрасиво переносится или обрезается.
- Нелокализованные строки: строки, которые захардкожены и не используют систему локализации.
- Комбинации отдельных предложений или абзацев, которые заданы таким образом, что их трудно будет локализовать (этим часто грешат программисты, пытаясь оптимизировать что-то и «облегчить» работу переводчикам).
- Проблемы с кодировкой, шрифтами: убедитесь, что шрифты поддерживают все необходимые символы для каждого языка и что глифы для таких символов не имеют проблем с дизайном (например, взяты из другого шрифта и выбиваются).
- Проблемы с написанием справа налево: пользовательский интерфейс на языке с письмом справа налево (RTL) должен быть размещен в зеркальном отображении макета слева направо.
- Нелокализованные изображения(например текстуры, содержащие текст).
Желательно, чтобы система локализации позволяла решать большую часть этих проблем, а также допускала возможность использования псевдо-локализации на любом этапе.
Машинный перевод у нас очень легко получить с помощью функции =googletranslate в выгрузке. Также предусмотрен импорт строк как нефинальных и исправление множества мелких ошибок, которые возникают при машинном переводе (например, вставка лишних пробелов или замена подчеркиваний).
Для тестирования интерфейсов добавлен “самый длинный” язык, что позволяет протестировать интерфейсы один раз вместо нескольких.
Для шрифтов есть отдельная утилита проверки на то, есть ли нужные глифы в них.
Пайплайн работы с переводами со стороны разработчика
Избежать примерно половины проблем с которыми мы столкнулись при локализации «Магии крови» можно двумя простыми действиями: добавить версионность текстов и отделить хранящиеся в игре тексты от отдаваемых на перевод.
Подходы: редактирование с выгрузкой и без неё
Есть два подхода.
- Первый позволяет править перевод прямо в редакторе.
- Второй запрещает любые правки кроме правок базового языка, вся работа с переводами идёт строго через переводчика с выгрузкой контента на перевод в Google Sheets. Плюсами первого подхода является скорость и простота работы с переводами, плюсами второго — больший контроль.
Мы используем второй подход. Любые изменения в базовом языке лок-кита (с которого переводится всё) обязательно выгружаются на перевод или проверку и (после проверки/правок переводчиком) загружаются обратно. У каждой строки есть версия перевода, которая увеличивается при изменениях текста базового языка. Это также решает проблему нескольких версий лок-кита и их синхронизации.
Также мы добавили возможность загрузки перевода как “временного”: мы можем выгрузить базовый язык, перевести его гугл-транслейтом на 10 разных языков, импортировать в проект как “временную” версию перевода и играть с плохим переводом, при выгрузке “того что нужно перевести” будет каждый раз выгружаться весь список этих строк. В колонке es-old будет “неактуальная” (или просто предыдущая) версия испанского перевода, переводчик может перевести нормально и вставить правильное значение.
Ключи локализации и генерация кода
Помимо простой работы с ключами мы используем генерацию C#-кода (для unity3d) чтобы было удобнее работать с локализацией из кода. Для этого у каждой строки есть флаг Static. Если флаг выставлен, то будет генерация метода в классе. Отсутствие таких строк вызовет ошибку времени компиляции, таким образом мы проверяем что не удалили и не переименовали важную строку (например, в интерфейсе).
Бывают два вида строк: статик и обычные. Обычные доступны только по ключу-техимени (GetTextById(«…»)). Для статик генерируется код, и можно обращаться к ним ещё и как к методу (соответственно если в коде написано LL.interface_block_window_button_reload() а ключа такого нет, то не соберется билд просто).
Все ключи-техимена имеют осмысленные имена и разделены точками. В редакторе сделана группировка (folding) по точкам. По точкам автоматом разбивается на группы (с вложенностью). Например, ключи interface.* будут в одном месте. Внутри interface. будет группировка по окнам, например interface.window_shop.* и все ключи, относящиеся к этому окну будут вместе.
Для временных ключей мы заранее заводим один статик LL.not_localized(«…») и всё так пишем. Очень просто потом в коде искать и заменять нелокализованные тексты.
Для каждой строки есть возможность добавлять комментарии для переводчиков и тех кто работает с текстом. Например, делать линки на другие строки (чтобы понимали о каком предмете идет речь в диалоге), ограничивать размер в символах или просто написать “это сообщение выводится, когда нет достаточного кол-ва софт-валюты”. При генерации кода эти подсказки также попадают в код, как подсказки методов. А при выгрузке локкита в столбец комментариев.
Для каждого ключа есть:
- Техимя(ключ)
- Флаг Static
- Комментарий для переводчиков
- Ограничение на кол-во символов (если 0 то нет ограничения)
- Список прилинкованных ключей (добавляются в комментарии при экспорте)
- Текущий номер версии текста (для каждого языка!), для базового он увеличивается при каждой правке базового языка (мы используем четные версии как “временные”, а нечетные как “финальные”),
- Переводы на каждый из языков (с версией, для переводов она увеличивается при импорте перевода, версия берется от базового языка отданного локкита)
Пример:
- у нас былы строка с версией базы 5 и версией перевода на английский 1,
- мы выгрузили и отдали на перевод,
- потом ещё несколько раз поправили и у нас уже версия база9.
- при импорте перевода у нас перевод1 будет заменен на перевод5,
- при следующей выгрузке он попадет в en_old а переводчику нужно будет перевести базовый9. Если там изменения в формате “пробел пропустили”, то он использует предыдущий перевод, если серьезные изменения, то переведет заново.
Языки
- Надо уметь выбирать список доступных языков (на которые локализуем).
- Базовый язык для перевода (например, русский, на нем пишем тексты)
- Язык по умолчанию для приложений (обычно английский, он показывается если мы определили язык системы, а у нас нет такого языка в списке поддерживаемых или если не смогли определить язык)
- Для каждого языка из списка есть флаг “доступен пользователю” (надо для того чтобы недоделанные лок-киты не показывать, например)
- В доступных языках есть “самый длинный”. Он берет из всех языков самое длинное значение и подставляет в игре. Это нужно чтобы проверить интерфейсы, например.
- Проверка шрифтов на соответствие локалям (отдельная утилита). Позволяет проверить, что в используемом шрифте есть все необходимые символы. Например, украинские буквы некоторые отсутствуют во многих кириллических шрифтах.
Поддержка импорта-экспорта в гуглодоки.
Можно выгрузить перевод (целиком или только непереведенное) в гуглодок, поправить там и импортировать обратно.
Важный момент: нельзя руками поправить перевод. Вообще никак. Можно только выгрузить, поправить и импортнуть. Все правки переводов только через импорт-экспорт делаются. Это позволяет избежать большого кол-ва проблем при работе над постоянно изменяющимся проектом. Ситуаций когда один раз перевели и больше ничего не меняется я не встречал ни разу.
Экспорт можно сделать для одного или нескольких языков. Импорт по одному или несколько сразу.
В выгрузке указывается версия ключей для базового языка (последняя на момент выгрузки), старая версия переводов, место для нового перевода (если не надо переводить, то там сразу будет копия старого текста), подсказки и комментарии.
Не так давно гугл поменял API и старые методы работы с гуглотабличками частично перестали работать (стали возвращать пустые данные). Мы уже перевели всё на новый API, если у вас похожая проблема, то просто перейдите на новый API.
Поддержка параметров в тексте локализации.
Можно вставлять параметры вида {_param_name_}, параметры с одинаковым именем считаются за один. Код для статиков генерируется. В сгенерированный класс сразу можно будет передавать параметры, проверка на кол-во аргументов и подсказки добавляются автоматически.
Что при экспорте можно выбрать
- Язык перевода (на который переводим)
- флаг частичный экспорт (экспортировать не всё, а только где версия меньше, т.е. только то что нужно переводить, а не весь лок-кит). Таким образом можно выгрузить и все тексты и только непереведенные.
- флаг “экспорт ошибок” (экспортировать ошибки — например несоответствие ключей при переводе).
- Экспорт линкованных ключей в комментариях: 3 варианта: “без ключей”, “тексты ключей”, “имена ключей”. Разным переводчикам удобнее работать с разными вариантами.
- Язык экспорта линкованных ключей (для варианта “тексты ключей”). Можно экспортировать как на языке оригинала, так и на том, на который переводим. Удобно при проверке лок-кита.
- Дополнительные языки. Можно экспортировать ещё несколько языков, которые попадут в лок-кит (это иногда упрощает работу над переводом, можно переводить сразу с двух языков на третий).
При экспорте в гугл-таблице для каждого не-базового языка будет 2 столбца: old_en и en
В первом старая версия перевода, во второй надо написать новую (если не поменялась то просто скопировать и импортнуть). Иногда бывают незначительные изменения типа лишнего пробела. И перевод остаётся прежним, переводчику в этом случае достаточно проверить что старая версия подходит.
Что у нас получилось (описание тулзы)
Как открыть редактор локализации
Открывается через Custom tools -> Localization Editor в юнити
Вкладки в редакторе
Вкладка Языки
 |
На этой вкладке можно добавлять новые языки и настраивать их видимость.
Базовый язык для перевода
Это язык на котором пишутся все тексты. С него идет перевод на другие языки. В нем самая актуальная версия текстов. Менять его не следует.
Язык по-умолчанию для приложения
В коде есть автоопределение языка. Если подходящего нет, то будет выбран этот. Как правило, это английский. Например у пользователя выбран язык системы туркменский, а у нас есть переводы только на русский и английский. Будет выбран язык по-умолчанию в этом случае.
Языки для перевода
Это языки на которые можно переводить (включая базовый).
У каждого языка есть галочка “разрешить к показу пользователю”. Если она не стоит, то этого языка не будет в списке доступных пользователю языков. Используется например чтобы подготовить перевод, но он ещё не финальный и мы хотим чтобы в игре были только русский и английский, но не было французского.
Также тулза умеет возвращать “самый длинный” язык. В этом случае из всех языков (не важно стоит галочка или нет) выбирается самый длинный перевод и подставляется в виде текста.
Вкладка Локализация
 |
Страницы (листы в гглотабличке)
В этой вкладке содержатся все локализуемые тексты.
Все ключи разбиты по “страницам”, каждая страница попадает на отдельный лист в гуглотабличке при выгрузке.
Можно переносить ключи и группы ключей между страницами, это сделано для удобства работы с ключами (например, имена монстров на странице monsters и т.п.).
Страницы можно удалять, добавлять, создавать и переносить ключи между страницами (из контекстного меню сразу для группы ключей). Каждая страница лежит в отдельном xml-файле.
Также есть специальный чекбокс “эта страница заполняется из кода”, это было сделано для одного из внешних проектов, подробно разбирать в статье не буду.
Фильтры
Ключи на странице для удобства можно отфильтровать. в поле “Фильтр” вводится текст и остаются только ключи, которые содержат введенный текст в названии ключа или в одном из переводов.
Показывать языки
Кнопки позволяют скрыть ненужные языки (столбцы) для удобства работы.
Ключи локализации
 |
 |
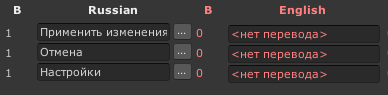 |
ТехИмя ключа локализации
У всех ключей-техимен локализации есть осмысленное имя. Имя может состоять из латинских букв, цифр, знаков подчеркивания и точек.
Точки служат для разбивки ключей на группы. Например, interface.window_shop.*
можно будет свернуть и развернуть все ключи начинающиеся на interface, или все ключи window_shop внутри группы интерфейс. Это удобно для поиска и группировки однотипных ключей.
Элементы управления ключом локализации
- Кнопка со стрелочкой около имени ключа позволяет переместить ключ или группу ключей на другую страницу.
- Кнопка “удалить” позволяет удалить ненужный ключ. Удаленные случайно ключи можно вернуть на вкладке “Настройки” (если не очищали список удаленных).
- Столбец с буквой “С” в заголовке позволяет поставить чекбокс “статический ключ”, для таких ключей кнопкой “Generate class LL” генерируются методы (код класса), который можно использовать из C#.
- Столбец “Ключ” содержит имя ключа, тут же его можно переименовать. Сохранение изменения имени ключа по клавише Enter.
- Поле Comments и кнопка “…” рядом с ним служат для добавления комментариев. При нажатии кнопки с тремя точками откроется окно добавления комментариев для переводчиков.
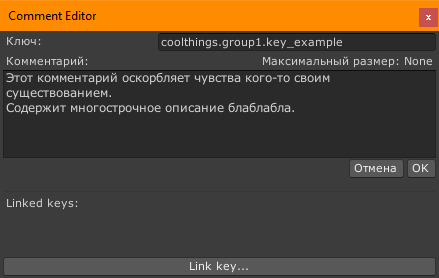 |
Кнопка link key позволяет к комментариям текущего ключа прицепить ссылки на другие ключи, которые упоминаются в тексте. Например, текст инфла “повышает скорость атаки на 20%”, можно прицепить к нему ссылку на “скорость атаки”, чтобы сразу в комментариях видеть как переводили это слово. При выгрузке для переводчиков там можно выбрать что показывать — названия ключей или их текущий перевод (и на какой язык перевод). Если прилинкованы ключи, то вместо трех точек на кнопке пишется кол-во прилинкованных ключей.
 |
 |
- Столбец MaxChars позволяет задать максимально допустимое число символов в тексте ключа. Например название абилки может быть ограничено 20 символами. При экспорте ошибок в файл (чтобы их исправили переводчики) ключи с превышением размера будут попадать в partial-экспорт список. Ограничение общее на все языки. Задать разное для разных языков нельзя (это не имеет смысла). Там же можно сделать пресеты, если нужно, например, добавлять одно и то же ограничение для большого числа ключей.
 |
- Столбец с буквой В обозначает версию текста для каждого ключа. При каждом изменении текста (сохранённом) версия ключа увеличивается автоматически. У всех остальных языков тоже есть версия. Если она меньше текущей, значит перевод устарел и при выгрузке он попадет в список ключей которые надо перевести заново или поправить или просто отметить, что перевод актуален (про это в описании вкладки Google docs). Около номера версии может рисоваться звездочка. Это означает, что текст перевода — временное говно, переведенное гуглтранслейтом или кем-то, кто не знает английского, чтобы там было “хоть что-то в переводе” (или просто переводчик сказал что это не финальный вариант перевода). Такие ключи можно выгрузить для актуализации.
Правка текста ключей
 |
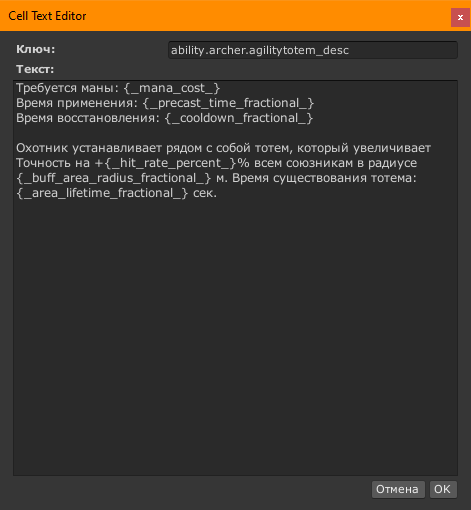 |
При нажатии на кнопку рядом с русским текстом, открывается вот такое окно. Можно поправить текст базового языка. Тексты переводов править нельзя, это специально сделано для защиты от очень умных. Вся правка переводов идёт через выгрузку локкита и импорт переведенного локкита.
Параметры в ключах
В тексте ключа могут содержаться параметры. Параметры служат для подстановки в ключ других значений.
Пример:
“Увеличены: Скорость атаки на +{_attack_speed_add_}, Скорость передвижения на +{_move_speed_percent_}% и Шанс критического удара на +{_crite_rate_add_}. Уворот снижен на {_dodge_rate_decrease_}.”
Параметры обрамляются фигурными скобками {} и должны содержать осмысленное имя. Из названия параметра должно быть понятно что туда передавать из кода, а не просто param1 param2. Из-за особенностей работы с гуглотаблицами (при автоматическом переводе на некоторые языки с помощью =googletranslate() удалялись куски в фигурных скобках) было решено названия параметров обрамлять ещё подчеркиваниями и слова в названии также разделять подчеркиваниями. Не использовать пробелы и большие буквы. Можно использовать в названии параметров только маленькие буквы латинского алфавита, цифры и подчеркивания. В противном случае автоматический перевод нужно будет долго править руками, так как он переводит и ключи.
Кол-во и имена параметров должны совпадать во всех языках. Если они не совпадают, тулза считает это ошибкой перевода и такие ключи попадут при выгрузке в список.
При генерации кода названия параметров будут подставлены в метод автоматически и описание метода сгенерировано с полным текстом. Если метод присутствует, а ключ удален, то собрать клиент не получится, будет выдана ошибка.
Дополнительно мы ввели внутри правила именования параметров:
- если нужно, чтобы число показывалось с дробной частью, то имя параметра должно оканчиваться на _fractional,
- если число выводится в процентах, то надо дописать в конце параметра _percent.
В коде оно всё равно выводится правильно, но это давало больше контекста переводчикам и программистам и уменьшало кол-во вопросов от последних.
Вкладка Google Docs
 |
Общий принцип работы тулзы
Все тексты базового языка правятся в тулзе. Потом делается выгрузка нужных текстов для перевода в гуглотаблицу. Когда тексты переведены (гуглтранслейтом или переводчиком), то переводы импортируются обратно в тулзу. Править переводы внутри тулзы нельзя! Это сделано специально для защиты от особо умных. Можно только выгрузить, поправить в табличке и импортировать обратно.
Авторизация
 |
Для работы с гуглотаблицами нужно авторизоваться, используя свой гугловский аккаунт. Выгруженные документы можно пошарить переводчикам.
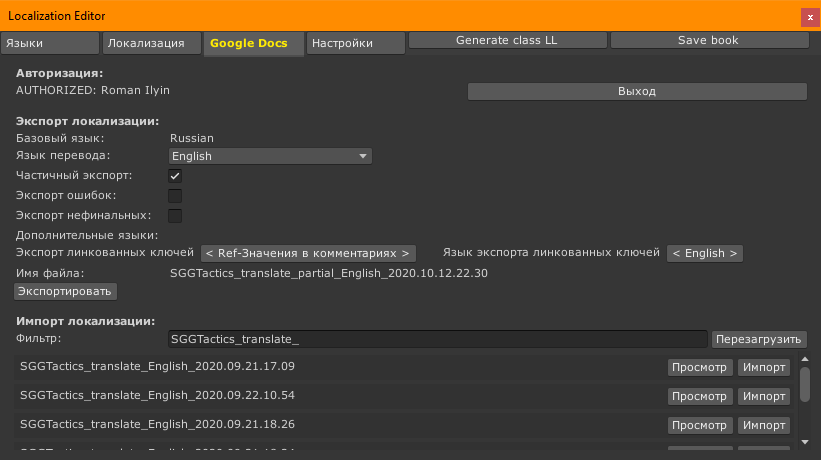
Экспорт локализации
Базовый язык
Просто показывает базовый язык, для информации.
Язык перевода и Дополнительные языки
Выбираем язык на который хотим переводить. Для этого во вкладке языков должно быть добавлено минимум два языка. Базовый и ещё один. В списке будут доступны только те языки, которые пользователь добавил во вкладке “Языки”.
Если нужно выгрузить сразу несколько языков, то остальные выгружаются проставлением галочек в разделе “Дополнительные языки”. Например, у нас есть русский и нормальный перевод на английский. А мы хотим переводить на немецкий. Мы можем указать язык перевода “немецкий”, а дополнительно (для удобства переводчика) выгрузить ещё и английский в дополнительных языках. Они все попадут в табличку.
Частичный экспорт
Если этот чекбокс не стоит, то выгружаются вообще все ключи которые есть в локките (полный локкит). Если чекбокс стоит, то выгружаются не все ключи, а только те, которые надо исправить.
В этот список попадают ключи, версия перевода которых меньше чем версия базового языка. Т.е. изменившиеся ключи и ключи без перевода вообще.
Экспорт ошибок
При включенном чекбоксе “частичный экспорт” в выгрузку попадают не все ключи, а только те что без перевода или версия которых устарела. Если включить чекбокс “экспорт ошибок”, то туда добавляются ещё и ключи с ошибками (например, несовпадающие имена и кол-во тегов, превышение размера в символах и т.п.).
Чекбокс “for all addition” проверяет ошибки ещё и для дополнительных языков, а не только для языка перевода (они тоже попадут в выгрузку).
Экспорт не финальных
При включенном чекбоксе “экспорт нефинальных” в выгрузку попадают также все ключи, для которых при импорте не был проставлен чекбокс “финальный перевод”.
Экспорт линкованных ключей
Тут можно выбрать вид, в котором линкованные ключи попадут в комментарии. Доступно три варианта: Без ref-ключей (будут только комменты, написанные вручную), Ref-ключи в комментариях (помимо коммента будет список ключей), Ref-значения в комментариях (будет подставлен перевод прилинкованных ключей, сбоку можно выбрать язык из которого будет взят перевод)
Имя файла
Генерируется автоматически. Подставляется partial если это частичный экспорт, проставляется дата экспорта (для удобства, не используется при импорте).
Импорт переводов
В нижней части окна есть список файлов, относящихся к данному проекту у вас на гугл-диске (фильтр по имени). Напротив каждого файла есть две кнопки: “посмотреть”(открыв файл в браузере) и импортировать (открывает окно импорта).
 |
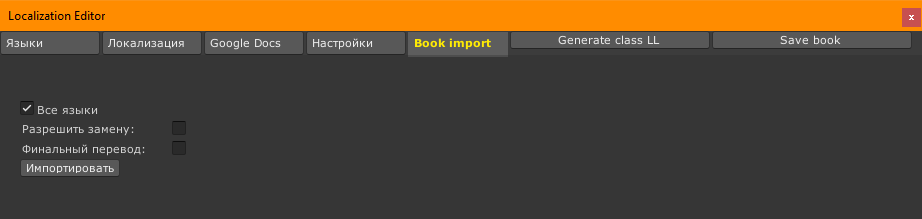 |
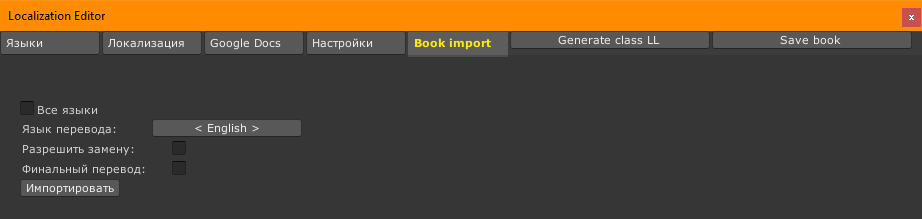
Там есть чекбоксы:
Все языки / Язык перевода
Чекбокс “все языки”. Когда включен, импортирует переводы не только для выбранного языка, но и для всех дополнительных.
Когда выключен, то появляется выпадающий список с языками, доступными для импорта.
Разрешить замену
По умолчанию заменяются только переводы ключей, версия перевода которых больше версии перевода в тулзе (только новые), старые не изменяются. Это сделано чтобы случайно не затереть нужный при работе с полным локкитом.
Если чекбокс включен, то заменяются также ключи с версией РАВНОЙ версии в тулзе.
Кнопка Импортировать
Импортирует переводы с выбранными параметрами
Вкладка Настройки
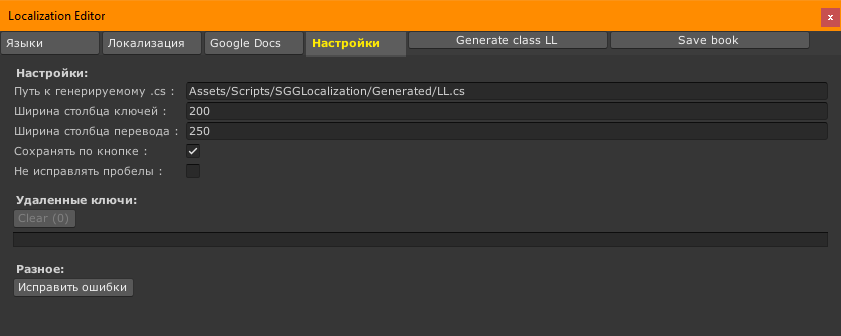 |
Общие настройки
Путь к генерируемому .cs файлу для статической локализации — указывает где он лежит. Файл полностью заменяется новым.
Ширина столбца ключей — в пикселах. Настраивается, чтобы видеть ключи целиком.
Ширина столбца переводов — в пикселах. Настраивается, чтобы видеть тексты целиком. Но рядом с текстом есть кнопка всегда, чтобы посмотреть его удобно с разбиением на строки.
Сохранять по кнопке — если выключить, то будет сохранять автоматически после каждого изменения. Удобно для небольших проектов.
Не исправлять пробелы — отключает часть фиксов (удаление лишних пробелов в начале и в конце, правки пробелов в ключах подстановки и т.п.), лучше пусть исправляет.
Удаленные ключи
Тут будет список ключей которые недавно были удалены. Их можно восстановить или очистить список.
Разное
Кнопка “Исправить ошибки” позволяет исправить ошибки ручного редактирования xml (не все, только некоторые). Лучше не правьте руками xml.
Generate class LL (вкладка-кнопка)
Генерирует код для статической локализации. В PixelWars используется только один такой ключ: not_localized.
Кнопка Save
Отключается в настройках. При большом кол-ве текстов автосохранение после каждого изменения тормозит. Для маленьких проектов мы оставили возможность автосохранения, для больших сохраняем руками по кнопке. Кнопку нужно нажимать после каждого редактирования текстов, иначе они не сохранятся.
Пример чеклиста работы с текстами
(был написан для одной из студий которая лицензировала тулзу)
Добавление новых текстов (вики и код)
Название (тех-имя) ключей задают гд.
Оно должно быть осмысленным. Название ключей на английском, не надо писать “posoh_s_zolotymi_sharikami_na_rukoyati”.
Если нужен новый ключ — согласуйте с гд!
Для всех новых интерфейсов обязательно указывается в вики какие ключи используются (группа, без деталей, например interface.window_shop.*). Если статьи с этим интерфейсом нет, то указывается в таске.
В название ключа добавляются префиксы, поясняющие что это (например, btn_ для кнопок, caption_ для заголовков окна, label_ для заголовков раздела, text_ для просто текстов и т.п.). Тут главное чтобы было понятно что это за ключ и что он делает из его названия.
- все параметры новые называем с подчеркиваниями по бокам {_tag_}, а не {tag}!
- для каждого окна свои ключи, чтобы можно было потом отдельно поменять
- если в тексте используется какой-то существующий текст (названия статов и т.п.) то линкуем ключ стата к ключу текста. это облегчит работу переводчика потом.
Создание новых ключей (в тулзе)
1) добавляем ключи (вечером раз в день)
опционально (если требуется срочно “хоть какой-то перевод” т.е. Pseudo-Localization):
1.1) выгружаем сразу partial (убрав галку про нефинальные! поставив галку “экспорт ошибок”)
1.2) переводим как гуглтранслейт, импортим как нефинальные (со снятой галочкой “финальный перевод”)
1.3) выгружаем ещё раз partial (убрав галку про нефинальные! поставив галку “экспорт ошибок”), если есть ошибки (в тегах как правило), то исправляем их, импортим как нефинальные! (со снятой галочкой “финальный перевод”). Повторяем пункт 1.3 пока не исчезнут ошибки (не останется ключей в частичной выгрузке)
2) выгружаем партиал поставив галку «включая нефинальные» и “экспорт ошибок”, отдаем переводчику.
3) когда переводчик перевела:
импортируем как финальные (галочка “финальный первод” стоит, галочка “разрешить замену” — нет).
3.1 выгружаем ещё раз partial (убрав галку про нефинальные! поставив галку “экспорт ошибок”), если там есть ошибки (хоть какие-то ключи попали), то отдаём переводчику их поправить, дожидаемся правок и импортируем с установленными галочками “финальный перевод”, “разрешить замену”. Повторяем пункт 3.1 пока ошибки не исчезнут.
Изменение уже добавленных текстов
1) изменяем русский текст в тулзе
2) выгружаем партиал поставив галку «включая нефинальные», “экспорт ошибок”, отдаем переводчику
3) как она отдаст импортим как финальные: включены галочки (“финальный перевод”), “разрешить замену”. повторяем пункты 2, 3 пока не будет пустая дока в партиал.
Дополнительно (best practices)
Что происходит когда нужного ключа нет
В этом случае возвращается техимя ключа (мы ещё обрамляли его звездочками в этом случае). Таким образом вместо “нет перевода” или “заголовок пустой” QA могут сразу сказать какого ключа нет и понять что с ним не так (название в коде не совпадает или просто не добавили ключ).
Помимо этого в лог выводится ошибка, а в релизе в систему аналитики отправляется эвент с именем ключа (это не часть системы локализации, но очень удобно).
Вёрстка текста
Поскольку мы работаем с юнити и TextMeshPro, то поддержка rich text и кастомных смайлов там есть “из коробки”. Дополнительно ничего делать не надо.
Туда же относятся неразрывность (не отрывать символ валюты от цифр) и прочие вещи. Всё уже есть в TMP!
Подсветка терминов в тексте
“прикольно было бы сделать как в Tyrany — там все термины подсвечиваются в тексте и попапчик при наведении райзится с пояснением”
Это не задача локализации, плюс уже реализовано тегами в TextMeshPro. Делается элементарно. Искать термины по названию и добавлять подсказки не надо по понятным причинам.
Локализация графики
В статье мы не стали касаться локализации графики, так как все это делают по-разному. Общий принцип там такой: все локализуемые фразы переводятся как обычный текст, потом вставляются руками на текстуры (если это например граффити), нужные текстуры по выбранному языку подгружаются.
Также мы делали шейдер текстовых декалей для размещения надписей на стенах (в мобильном проекте). Но это ничем не отличается от обычных надписей в интерфейсе и рассматривать отдельно смысла мало.
Как лучше называть ключи и параметры
Техимена ключей
Общий принцип — а как вам удобнее их будет группировать потом?
Для интерфейсов мы обычно делали общую группу “interface.”
В ней группы для каждого окна (interface.settings.), внутри для вкладок окна (interface.settings.sound. ) и т.п.
Для статов отдельная группа stats.:
Примеры:
stats.strength_name = “Шанс критического урона”
stats.strength_short_name = “Крит.шанс”
stats.strength_description = “Влияет на вероятность нанести критический урон”
Так всё что относится к одному стату будет в выгрузке и редакторе находиться рядом.
Для персонажей например
characters.npc.<техимя персонажа>_name
characters.monsters.<техимя персонажа>_name
characters.bosses.<техимя персонажа>_name
Кол-во уровней фолдинга можно увеличивать переименованием нужных ключей (заменой подчеркивания на точку).
В коде мы стараемся формировать название ключа автоматически из техимени где это возможно. Например: “characters.npc.”+<техимя персонажа>+”_name”.
для квестов и диалогов квеста скорее всего название ключа будет содержать и квест и “кто говорит”.
Пример:
dialogs.q_stupid_quest_coyotes.d_01_intro.d_001_merchant_male_hero_female = “Привет, великая воительница, я хотел бы попросить тебя принести 10 шкур койотов и фапотьку!11”
dialogs.q_stupid_quest_coyotes.d_01_intro.d_002_hero_female_merchant_male = “И тебе привет, купец!”
quests.q_stupid_quest_coyotes.quest_name = “Шкуры и фапотька”
В диалогах важно соблюдать порядок фраз (просто добавьте номера фразам, это можно сделать даже автоматически в некоторых случаях). Также нас часто просили указывать пол говорящего и того к кому обращаются помимо имен говорящих. Сделать это можно в комментариях или в названии ключа — как удобнее.
Помещать диалоги внутрь квеста (quests.q_<имя_квеста>.dialogs.) или отдельно (dialogs.q_<имя_квеста>.) решать вам. У нас было много диалогов и мы хранили отдельно, нам так было удобнее.
По возможности храните одинаковые сущности на отдельных листах. Тогда проще будет искать их. Называйте листы осмысленно, например “quests” или “interface”.
Техимена параметров подстановки
Общий принцип — должен быть понятен контекст.
Старайтесь называть одни и те же параметры единообразно, чтобы программистам не приходилось дублировать код.
Примеры:
Требуется маны: {_mana_cost_}
Время восстановления: {_cooldown_fractional_} сек.
Охотник выпускает в цель две пламенные стрелы. Каждая из них наносит {_attack_damage_} единиц огненного урона и поджигает противника на {_influence_duration_fractional_} сек.
Горящий противник теряет {_hp_decrease_} единиц здоровья раз в {_period_fractional_} сек.
Требуется маны: {_mana_cost_}
Время восстановления: {_cooldown_fractional_} сек.
Не промахивается. Без критических попаданий.
Канонир бросает гранату, которая наносит {_attack_percent_} единиц электрического урона всем целям в радиусе {_aoe_area_radius_fractional_} м. На месте взрыва образуется грозовое облако. Все противники, попавшие в облако, получают на {_damage_increace_percent_}% больше урона в течении {_influence_duration_fractional_} сек.
Время существования облака: {_area_lifetime_fractional_} сек.
Склонения, род и прочие сложные штуки
Кратко: вам это скорее всего не нужно!
В чем сложность подстановок
Делать автосборку названий довольно сложно. Давайте разберем на примерах:
Предположим, что мы хотим чтобы название (пока только в именительном падеже!) указывало на статы и прочие характеристики предмета (как в диабло).
Название состоит из: “определение”(прилагательное) + “тип предмета”(существительное) + “идентификатор принадлежности”(существительное)
И прилагательное и идентификатор принадлежности зависят от рода/числа.
Примеры:
Красный меч/Красная секира/Красные стрелы
la feu DU dragon — огонь дракона
la feu DE LA terre — огонь земли
la feu DES maudits — огонь проклятых
Также меняется порядок слов во многих языках (корейский, французский, испанский):
во французском определение (префикс) будет стоять после обозначаемого слова в этом случае, например:
la feu délétère de la terre — гибельный/смертоносный огонь земли, дословно: огонь смертоносный земли
в ит: la fiamma disastrosa de la terra
Также одно и то же слово в разных языках может быть разного рода! Так исторически сложилось.
Заметьте, это пример только в именительном падеже без склонений!
Так что если есть возможность вписать название в текст без подстановок — сделайте это и не морочьте голову переводчикам! Если нет, то придется выстраивать довольно сложную систему. Подумайте: точно ли оно вам надо? Не проще ли назвать предметы сразу как надо и не заморачиваться с такими штуками?
Пример реализации с помощью нашей системы
Возьмем простейший случай: название собирается в зависимости от класса и статов из префикса, существительного и постфикса. Используется отдельно, не подставляется в диалоги и не склоняется.
Тогда для большинства актуальных языков мы будем использовать одну из четырех групп:
- masculine (мужской род),
- feminine (женский род),
- neuter (средний род),
- plural (множественное число).
Заведём отдельный ключ “naming_format”, в котором будет формула сборки текста.
Примеры того что там может быть в статах
[prefix_secondarystat|masculine] +[item_name] + [postfix_rarityclass] [prefix_class_attack_element_name] +[item_name] + [postfix_secondarystat|masculine]
Вместо плюсов там будет либо порбел либо артикли либо ещё что-то.
У нас будет 4 таких ключа (или можно заранее договориться что все предметы одного класса в этот слот только в мужском или только в женском роде, тогда будет меньше ключей).
Дальше в коде парсится ключ форматирования и собирается из составных частей. Префиксы типа английского a/an можно сразу добавить к названию в этом случае.
Группу рода мы будем указывать отдельно где-то, например в отдельном ключе или тегом, который вырежем.
Это пока только для одного словосочетания!
Пример сборных названий предметов из нашей игры:
https://docs.google.com/spreadsheets/d/1uXJyIRQ2R9OOTtba0EPK3BXcghlkr8r8AjrvIXKchHM/edit?usp=sharing
Аналогично для склонений/падежей (в каких-то языках их нет, в каких-то их больше чем в русском).
Ещё есть изменение формы слова от кол-ва предметов. С ними чуть попроще. Для числительных существует 19 групп, в каждой свои правила. Ознакомиться можно по ссылке:
https://developer.mozilla.org/en-US/docs/Mozilla/Localization/Localization_and_Plurals
Можно задать эти правила для каждого языка, записать в виде switch и пользоваться.
Общий вывод: если хочется использовать такие сложные формы подстановок, готовьтесь к куче проблем и плохо читаемому тексту (есть ещё и диалекты, слова-исключения и т.п.).
Пример готового решения для подобных штук:
https://github.com/messageformat/messageformat
https://github.com/axuno/SmartFormat
Теперь оцените насколько удобно будет переводчикам с этим работать и ещё раз задумайтесь — нужно оно вам или нет?
Скорее всего, если это не Diablo (т.е. у вас нет 100500 миллионов разных предметов генерируемых) и у вас нет отдельной команды для этого — оно вам не нужно. Если есть, то можно по аналогии с тем что я выше описал сделать, но это не на 5 минут задача, требующая обязательной проверки носителями языка.
Мы использовали такой подход:
У предметов был основной стат и второстепенные, также у двух классов предметов (оружия и доспехов) мог присутствовать элемент (элементальный урон для оружия и смена элемента для доспеха, по аналогии с Ragnarok Online). Предметы могли быть разной рарности.
Шаблоны правил именования naming_format мы сделали разными для обычного оружия, для элементального, для редких, аналогично для доспехов и т.п.
Префикс и постфикс выбирали в зависимости от редкости, наличия элемента, основного и вторичного статов (из них выбирали самый влияющий). У элемента был приоритет перед всем остальным.
Склонения («вам выпал обычный меч» или «вас ударили обычным мечом») мы не делали, так как это в разы увеличивало объемы локализации и сложность.
Про стоимость разработки
Поскольку тулза локализации получилась довольно удобной, мы в итоге решили продавать лицензии на неё.
Мы изначально не рассматривали вариант ассетстора, так как он требовал отдельной постоянной техподдержки (в том числе ответов на вопросы не очень продвинутых пользователей), а нам не хотелось этим заниматься. Мы решили, что лучше продать одну копию одному юрлицу (B2B) за $5000, чем 100 копий B2C по $50 за ту же цену.
Мы работали исключительно с юрлицами, предоставляя лицензию в формате «на любое число проектов для одного юрлица». Все обновления мы раздавали бесплатно (всё равно сами используем её во всех наших проектах, нам не сложно). В итоге все довольны, нам удобно, некоторые “хотелки” мы потом добавляли бесплатно (и сами используем часть из них).
Такой формат позволил в итоге окупить разработку системы локализации со всеми итерациями примерно за 3 года без отрыва от производства своих продуктов.
Что в планах улучшить
Перевод на новую систему UIElements
Мы уже перевели большую часть внутренних редакторов на UIElements и GraphView, там и отображение удобнее и код редактора писать проще. В планах сделать версию системы локализации на UIElements (и полностью перейти на неё).
Замена локализации для пользовательских переводов
Возможность пользователю положить файл с переводом части ключей, чтобы они использовались вместо основного перевода. Мы хотим это использовать для фанатских переводов игры (естественно, с проверкой соответствия ключей нашим).
Основная локализация будет храниться в одном файле, модерам без тулсета не очень удобно работать с этим, а мы хотим добавить поддержку неофициальных переводов не ломая основную систему.
Поддержка эмодзи
У нас в данный момент нет необходимости использовать эмодзи в локализации, но на будущее планируем сделать замену эмодзи с кодами разных сервисов отправки.
Получение списка символов
Получение множества символов для генерации текстур фонтов (в планах есть, пока сделали по чарсетам языки целиком). Также есть отдельная утилита для проверки шрифтов на то, все ли символы в них есть нужные или нет.
Standalone версия
Версия не в виде редактора, а в виде отдельного приложения. Думаем над этим, но пока не было необходимости.
Поддержка Unity Localization
https://docs.unity3d.com/Packages/com.unity.localization@0.8/manual/index.html
Пока находится в превью. В планах (далеких) добавить совместимость, когда пакет выйдет из превью, если в этом будет смысл.
Там есть полезные фичи, но всё в R&D, так что пока не хочется тратить на это время.
Интеграция с системами Text To Speech
Планируем через какое-то время добавить возможность генерации озвучки диалогов для черновой озвучки игры. Это может быть удобно для препродакшна, так как финальная озвучка делается обычно в самом конце, а надиктовывать голосом самим черновую долго.
Мы уже делали такое в 2012, хотим теперь использовать какой-то из готовых ассетов с бОльшим числом поддерживаемых TTS-движков, чтобы можно было выбрать голоса. В идеале с поддержкой эмоциональной окраски.
В реалтайме генерировать озвучку в теории тоже можно, но мы не видим в этом смысла, так как TTS озвучка — это плейсхолдер, а не финальное решение для продакшена.
Прочие хотелки
(нам пока не нужно такое, но может вам нужно, если будете делать свою систему с нуля)
- «sisulizer как внешняя тулза»
- мы её не используем, но люди спрашивали, наверное может быть удобно. мы сразу отдаем переводчикам в google sheets.
- «под разные разрешения обрыв строки может стоять в разных местах. разные теги для разных обрывов. Т.е. каждый тег имеет версию под которую работает, а остальные игнорируются. «
- мы такое не используем, так что делать не стали, но это легко решается простой заменой
- “указал тег — подсосало из кода в рантайме”
- мы от такого отказались, но легко добавляется простой заменой при желании, для себя считаем такой подход создающим проблемы
- «анализ сцены и префабов на предмет нелокализованных компонентов»
- мы так не делаем, сразу используем “LL.not_localized(“нелокализованный текст”)”
- «локализация арабских языков которые справа налево (равно как изменение выравнивания текстов и т.п.). В самих текстах проблемы загрузить арабский перевод нет, а вот изменение выравнивания затрагивает интерфейсы, которые у всех реализованы по-разному.»
- В планах отдавать LTR/RTL для языка.
- Localization/unicode related for Steam (от анизотропера): «Steam usernames are UTF8 and frequently contain ƃᴉzɐɯ∀ st(тут эмоджи с радиацией)ff. Reassembly uses Google’s Droid Sans Fallback and Open Sans Emoji to provide additional characters for rendering usernames, and SDL_ttf or Cocoa/NSFont to actually render the text, depending on the platform. In an ironic twist of fate, the first version of this article was lost because wordpress choked on a U+E10D (rocket) character.»
- Мы пока не делали, но должно решиться тупо заменой шрифта на поддерживающий эмоджи и использовании его для отображения стим-ников. В планах (далёких) есть.
Ссылки по теме
https://habrahabr.ru/post/237725/ Локализация приложений для китайского рынка
https://habrahabr.ru/post/128536/ Особенности локализации текста (перевод)
https://habrahabr.ru/company/miip/blog/324496/ Особенности локализации игр на иностранные рынки
http://wnfx.ru/pravila-lokalizatsii-prilozheniy-v-kitae/ Правила локализации приложений в Китае: деньги, связи и App Store
Когда-то мы с Александром Штаченко писали статью на тему локализации http://progamedev.net/localization/
https://habr.com/ru/post/694662/ неплохая статья про разницу подходов к локализации в UE и Unity
Какие готовые ассеты можно использовать в Unity, если не хочется делать свою систему?
Самым навороченным считается L2 Localization. Нас не устроил сам пайплайн, так что пришлось делать свою.
https://assetstore.unity.com/packages/tools/localization/i2-localization-14884
Также юнити сейчас начали делать свою систему локализации. Документацию на превью-пакейдж можно найти тут: https://docs.unity3d.com/Packages/com.unity.localization@0.8/manual/index.html



Свежие комментарии